The simplest way to give an LLM memory is to hand it a scratchpad: a single text file it can read and rewrite. This works up to a point. For a short conversation about a bounded topic, it is often enough.
It breaks down quickly once the conversation grows, the facts multiply, or the model needs to update something it recorded ten minutes ago. The reason is structural: a flat notepad has no shape. Everything lives at the same level, with no way to navigate to a specific fact without reading everything.
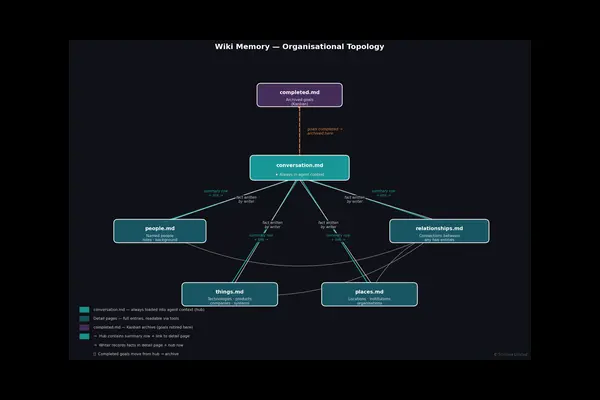
Our evaluation infrastructure uses a different approach — a typed wiki organised around a simple ontology. The advantages compound in ways that are not obvious until you see the wiki in use.
The Ontology
The wiki is divided into typed pages:
| Page | What it holds |
|---|---|
conversation.md | Always in context — participants, active goals, open todos |
people.md | Named individuals, roles, organisational affiliations, background |
places.md | Locations, organisations, institutions |
things.md | Technologies, products, tools, companies, concepts |
relationships.md | Connections between entities |
completed.md | Retired goals and resolved questions |
This is a classic library ontology — People, Places, Things, Relationships — applied to the contents of a conversation. Every fact the model records goes into exactly one page by type.
Here is what people.md looks like after a conversation about the LLM memory market:
## Deshraj Yadav
- **Role:** Co-founder, Mem0 [log:294] [checked]
- **Background:** Was a founding engineer at Uber. [log:294] [checked]
## Charles Packer
- **Role:** Co-founder, Letta [log:287] [checked]
- **Background:** Co-founded Letta, the commercial spinout of the MemGPT
research project from UC Berkeley. [log:287] [checked]And things.md for a technology entry:
## Zep AI
- **Type:** LLM memory management platform [log:282] [checked]
- **Founded:** 2022 [log:282] [checked]
- **Key differentiator:** Temporal knowledge graphs — tracks not just what
a user said but when they said it and how beliefs changed over time [log:282] [checked]
- **Primary enterprise verticals:** Financial services and legal tech [log:282] [checked]Why This Beats a Flat Notepad
Targeted retrieval. When a new turn mentions Zep AI, the model does not need to reload the entire memory. It reads things.md and navigates to the Zep AI section. A flat notepad forces a full read every time. As the conversation grows, the flat notepad grows with it — eventually consuming more context than it saves.
Typed updates. When a fact changes — Mem0’s founding year is corrected from 2023 to 2024 — the model knows exactly where to go: things.md, section Mem0, field Incorporated. In a flat notepad, updating a fact means finding and fixing every occurrence, with no guarantee of consistency.
Relationship separation. Keeping relationships in their own page prevents the common failure mode where entity facts and relational facts become entangled. “Letta was founded by Charles Packer” is a fact about Letta (in things.md). “Charles Packer and Shengding Hu are co-founders” is a relationship (in relationships.md). When you need to answer a question about the founding team, you know where to look.
Provenance for free. Every entry carries a [log:N] tag — the conversation turn where the fact was recorded. When a fact is later contradicted or updated, the model can trace back to the original source. The [checked] tag marks facts that have been cross-verified. A flat notepad has no natural place for this metadata.
Working memory separation. conversation.md is always injected into context. Everything else is loaded on demand. This implements a natural working memory / long-term memory split within a single conversation — the model always knows who is in the conversation and what the active goals are, without paying the full cost of loading all recorded facts on every turn.
The Compounding Effect
These advantages compound. A model with a typed wiki can handle a 50-turn conversation with 30 distinct facts more reliably than one with a flat notepad, not because it has more memory capacity, but because it can navigate its memory rather than scanning it.
The cost is a small amount of structure at setup time: defining the page types and giving the model a schema to write to. In our implementation this is a six-page wiki with a README index that takes a few seconds to initialise. The return is a memory system that stays usable as the conversation grows, updates without drift, and can be inspected and audited fact by fact.
The same principle applies to any retrieval-augmented system. The question is not just how much you can store, but how efficiently you can find and update what you stored. A flat store answers the first question. An ontology answers both.
This architecture is part of our ongoing memory evaluation research. See also our post on how we measure memory recall and precision.