
LLMs are increasingly used in contexts where they need to remember things: a running project, a client relationship, a multi-session research conversation. Evaluating how well they do this is harder than it looks.
The core problem is that the same fact can be expressed in countless ways:
| What was said in the conversation | What the model might write in notes |
|---|---|
| ”We decided to use PostgreSQL" | "Postgres was chosen for its ACID guarantees" |
| "Alice owns the auth service" | "Alice is responsible for authentication" |
| "The API must ship by 15 May" | "Deadline for the API: end of Q2” |
String matching fails completely here. A model that perfectly remembers every fact will score zero if it paraphrases. A model that copies sentences verbatim will score high even if it understood nothing. Neither is useful.
The QA-Probing Approach
Our evaluation is built around QA-probing: instead of comparing strings, we use an LLM to ask specific questions about a set of known facts and score the answers on the same 1–5 graded scale we use for entity extraction.
Every synthetic conversation is generated from a fact manifest — a structured inventory of facts that were explicitly introduced into the conversation and should be retained. For each fact, the manifest contains a probe question and an expected answer:
Fact: "Mem0 raised $23.5 million in its Series A"
Question: "How much did Mem0 raise in its Series A?"
Expected: "$23.5 million"At evaluation time, the evaluator reads whatever memory the model produced — whether that is a wiki, a summary, or simply the conversation transcript — and asks the probe question. The answer is scored 1–5:
| Score | Meaning |
|---|---|
| 5 | Fact correctly and fully captured |
| 4 | Core fact right, minor detail imprecise |
| 3 | Core fact present, secondary attribute missing |
| 2 | Fact present but materially wrong |
| 1 | Fact absent or directly contradicted |
Weighted recall is the mean of (score / 5) across all facts. Strict recall is the fraction of facts scoring exactly 5.
Two Memory Conditions
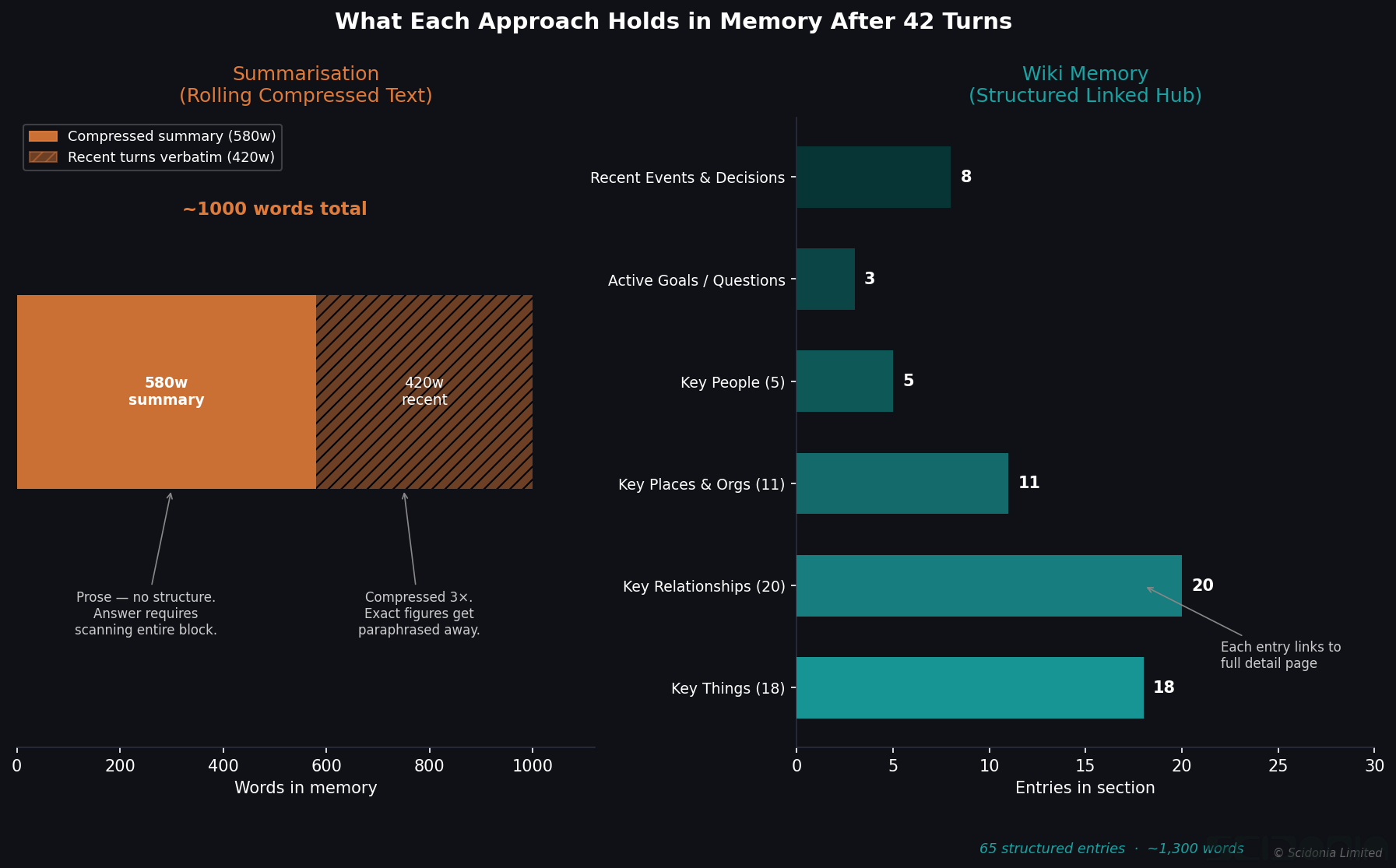
We evaluate two conditions:
Short-term (summarisation): The model answers from pure in-context memory — no external notes, no wiki. This measures how well the model retains facts stated earlier in the same conversation as the conversation grows.
Long-term (wiki): The model maintains a project wiki during the conversation — a set of structured markdown pages it reads and writes through a controlled API. After the conversation ends, we probe the wiki rather than the model directly. This measures whether the model correctly externalised what it learned.
Precision: Atomic Claim Verification
Recall measures what was captured. Precision measures whether what was written is actually correct.
For the wiki condition, the evaluator extracts every atomic claim from every wiki page and verifies each one against the original conversation transcript:
"Mem0 was founded by Taranjeet Singh and Deshraj Yadav" → check transcript → score 1–5
"Mem0's Series A was led by Sequoia Capital" → check transcript → score 1–5A claim scoring 1 is a hallucination — something written in the wiki that has no support in the conversation. This is the memory equivalent of the parametric injection problem we describe in our entity extraction hallucination post: the model writing things it knows from training rather than things it learned from the conversation.
Short-Term Memory: What Our First Results Show
In our initial evaluation, Claude Sonnet 4.6 was given a 20-turn conversation about the LLM memory market — covering companies like Mem0, Zep AI, Letta, and Qdrant, with specific facts about funding rounds, founders, and technical details that are unlikely to be in training data.
Short-term recall: 38% weighted, 5% strict across 20 facts.
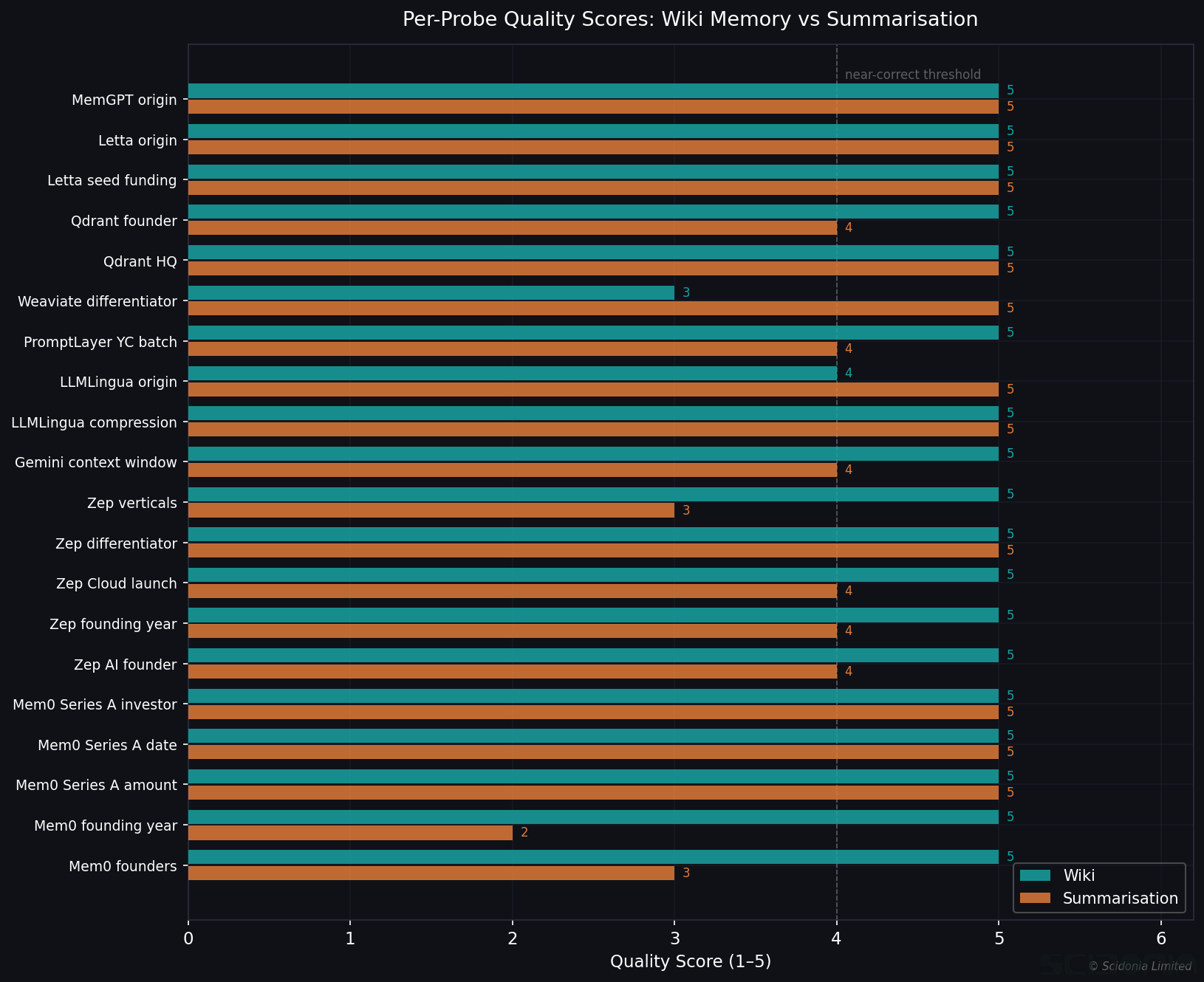
The pattern was revealing. Facts that overlapped with training knowledge were recalled well:
- “Letta is the commercial entity of the MemGPT research project from UC Berkeley” — score 5
- “Google Gemini 1.5 Pro reached 1 million tokens context in early 2024” — score 4
Facts that were genuinely novel — funding amounts, specific investor names, founding years of small startups — were recalled poorly or not at all. For 14 of the 20 facts, the model deferred to external sources rather than recalling from the conversation.
This is the inverse of the entity extraction hallucination problem. For extraction, the model injects training knowledge where document knowledge should be. For memory, the model fails to retain novel facts precisely because they are not reinforced by training knowledge. The boundary between what the model knows and what it learned in context is porous in both directions.
Why This Matters
If you are building an LLM agent that needs to track project facts, client preferences, or research findings across a conversation, the critical question is not “can the model answer questions in general?” but “can the model answer questions about things it was specifically told?” Standard benchmarks do not measure this. Our evaluation does.
The methodology — synthetic conversations with known ground truth, QA-probing for recall, atomic claim verification for precision — is designed to separate what the model remembers from what it already knew. That separation is what makes the measurement meaningful.
The evaluation framework is part of our ongoing ExtractionEval research. A follow-up post will cover long-term memory across sessions and the wiki writing pipeline.