In our entity extraction benchmark and hallucination analysis, every precision score depended on a second LLM checking whether each extracted item was genuinely supported by its cited phrases. We used Claude Sonnet 4.6 for this throughout.
A natural question follows: does it matter which model does the checking? And if a cheaper model can do it just as well, how much can you save?
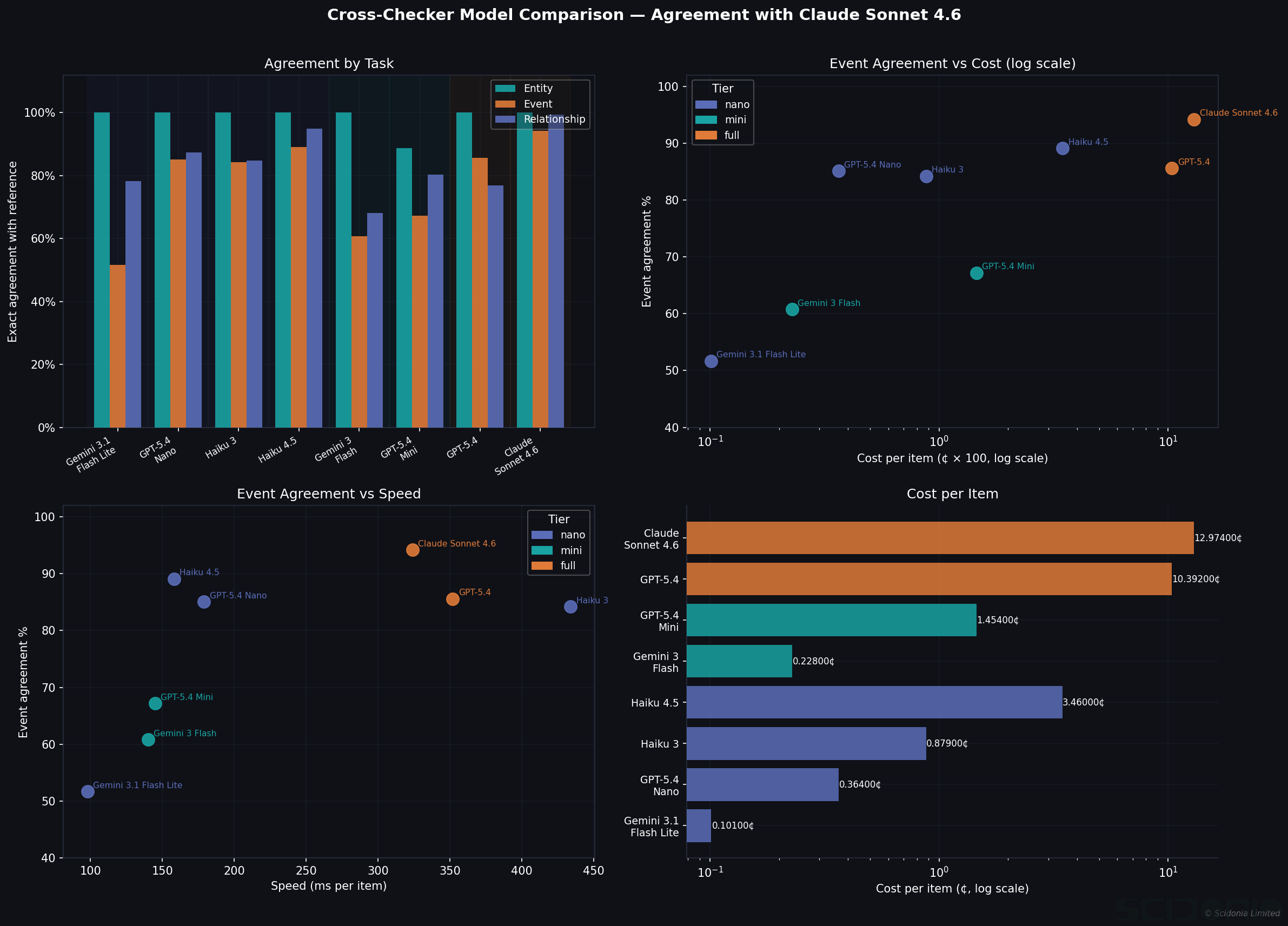
We ran a systematic comparison of eight models as quality scorers, using Claude Sonnet 4.6 as the reference standard and measuring agreement across three task types: entity, event, and relationship verification, plus a targeted hallucination detection test.
The Checking Step
Our cross-check pass works like this: for each extracted entity, event, or relationship, we retrieve only the specific phrases the extraction cited, then ask a scorer LLM to rate whether the item is genuinely supported on a 1–5 scale (5 = fully supported, 1 = no support in the cited text). Items scoring 1 are hallucinations; items scoring below a threshold are filtered out.
The question is whether a cheaper model produces the same scores as Claude.
Entity Checking: Price Does Not Matter
For entity verification, every model tested gives identical results — from the cheapest to the most expensive.
Gemini 3.1 Flash Lite at 0.0007¢ per item — roughly 200× cheaper than Claude Sonnet at 0.13¢ — achieves 100% exact agreement with Claude on entity scoring. If your pipeline handles entities only, use the cheapest available model as your checker. The savings compound quickly at scale.
Event Checking: Model Quality Matters
Event scoring is harder. Events require understanding temporal context, agency, and causality — and the models diverge significantly:
| Model | Agreement with Claude | Cost/item |
|---|---|---|
| Claude Sonnet 4.6 | 94% | 0.13¢ |
| Claude Haiku 4.5 | 89% | 0.04¢ (3× cheaper) |
| GPT-5.4 Nano | 85% | 0.004¢ (33× cheaper) |
| Gemini 3 Flash | 61% | 0.001¢ |
The Gemini Flash models show systematic scoring differences from Claude on events — not because they are wrong, but because they apply different thresholds for what counts as an “exact” event extraction. For event-heavy pipelines, Claude Haiku 4.5 offers the best cost-quality trade-off at 3× cheaper with only 5pp agreement loss.
Hallucination Detection: The Critical Test
Catching hallucinations is the most important job of the verification step. We built a targeted test: 20 relationships Claude confirmed were hallucinated (score 1) and 20 it confirmed were correct (score 5), then asked each model to classify them.
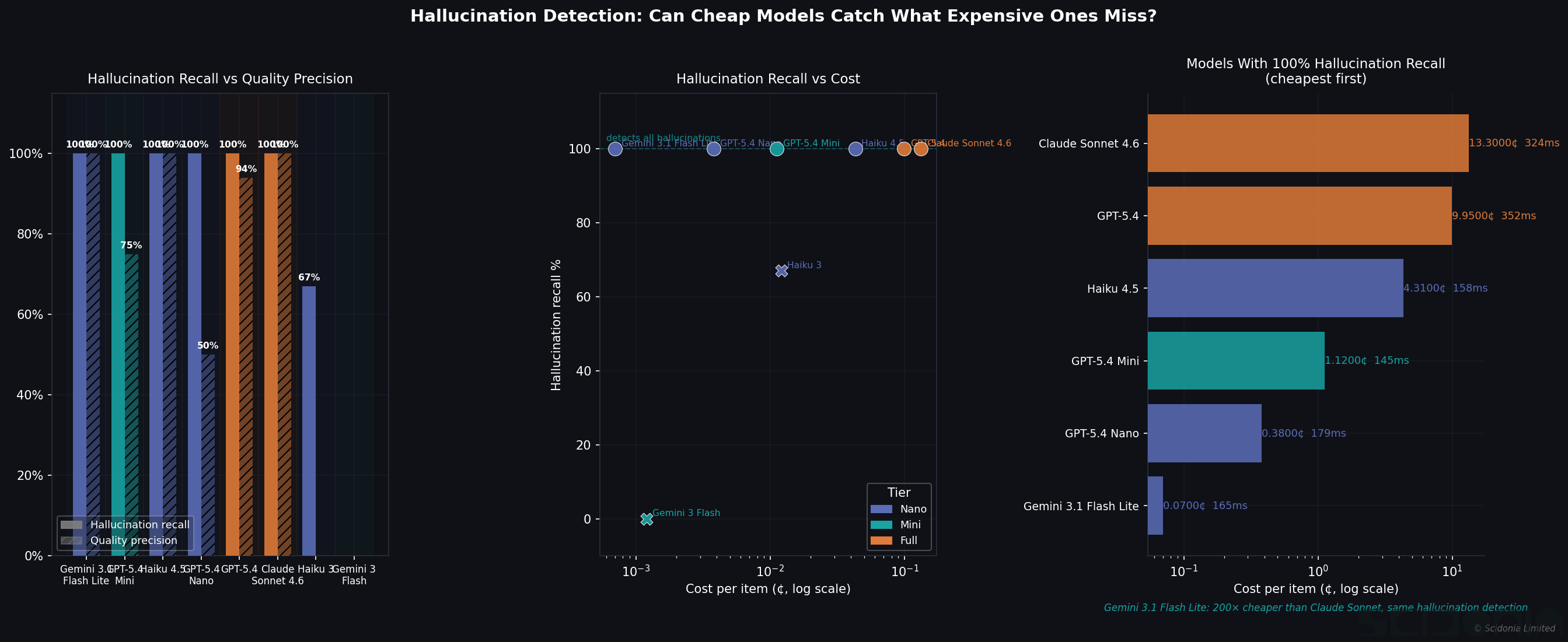
The headline result is striking: six of eight models achieve 100% hallucination recall, including Gemini 3.1 Flash Lite at 0.0007¢ per item. Detecting a hallucinated extraction costs essentially nothing when using the right model.
Two models failed: Gemini 3 Flash scored all items as 3 (uncertain) regardless of actual quality; Claude Haiku 3 missed 33% of hallucinations. Both are unsuitable for verification roles.
Quality precision — correctly identifying genuinely good extractions rather than over-flagging them — further separates the field. Claude Sonnet, Haiku 4.5, and Gemini 3.1 Flash Lite all achieve 100% here. GPT-5.4 Nano achieves only 50%: it catches every hallucination but also rejects half of the correct items. That is not a useful checker.
Practical Recommendations
| Use case | Recommended checker | Saving vs Claude Sonnet |
|---|---|---|
| Entity verification only | Gemini 3.1 Flash Lite | 200× |
| Entity + relationship | GPT-5.4 Nano | 35× |
| Entity + event + relationship | Claude Haiku 4.5 | 3× |
| Maximum precision | Claude Sonnet 4.6 | — |
The checker model has no impact on entity recall and a modest impact on event and relationship scoring. For most production pipelines running entity and relationship extraction, switching to Gemini 3.1 Flash Lite or GPT-5.4 Nano for the verification step reduces checking costs by an order of magnitude with no meaningful quality loss.
The exception is event extraction with high precision requirements — there, paying for Claude Haiku 4.5 is worth it.
Part of our ongoing ExtractionEval research. See also our PERSON entity extraction benchmark and hallucination analysis.