
Entity extraction is not a curiosity. It is infrastructure. When you run an LLM over a corpus of documents to build a knowledge graph, populate a database, or power a search and navigation layer, the extracted entities and relationships become the facts your system reasons from. Downstream queries, recommendations, compliance checks, and human decisions all flow through them.
This is precisely why hallucinations in entity extraction are more dangerous than hallucinations in a chatbot. A chatbot hallucination is visible — a user reads the wrong answer and notices. A hallucinated entity silently enters your knowledge graph, looks indistinguishable from a real fact, and begins to influence every query that touches it.
We measured how often three frontier models — Claude Sonnet 4.6, GPT-5.4, and Gemini 3 Pro — produce unsupported extractions during entity, event, and relationship extraction across eight open-licence documents. The results reveal something more subtle and more dangerous than pure fabrication.
What We Mean by a Hallucination — and Why the Term Can Be Misleading
In our benchmark, every extracted item must cite the specific phrase or phrases in the source document that support it. A score-1 item is one where the cited phrase provides no support for the extracted item — the entity, event, or relationship does not appear in the text the model claimed to have found it in.
But when we went back and verified the flagged examples against real-world sources, we found that most of them are factually true. The model did not invent the facts. It knew them already — from its training data — and injected them into the extraction, citing a phrase that happened to be nearby but did not actually contain the information.
This distinction matters enormously. It is the difference between an LLM making something up and an LLM telling you something real about the world that your document does not say. Both are wrong for knowledge graph purposes. The second is arguably harder to detect.
The Aggregate Numbers
Across all eight documents and all three tasks, unsupported extraction rates vary widely by model and by what is being extracted.
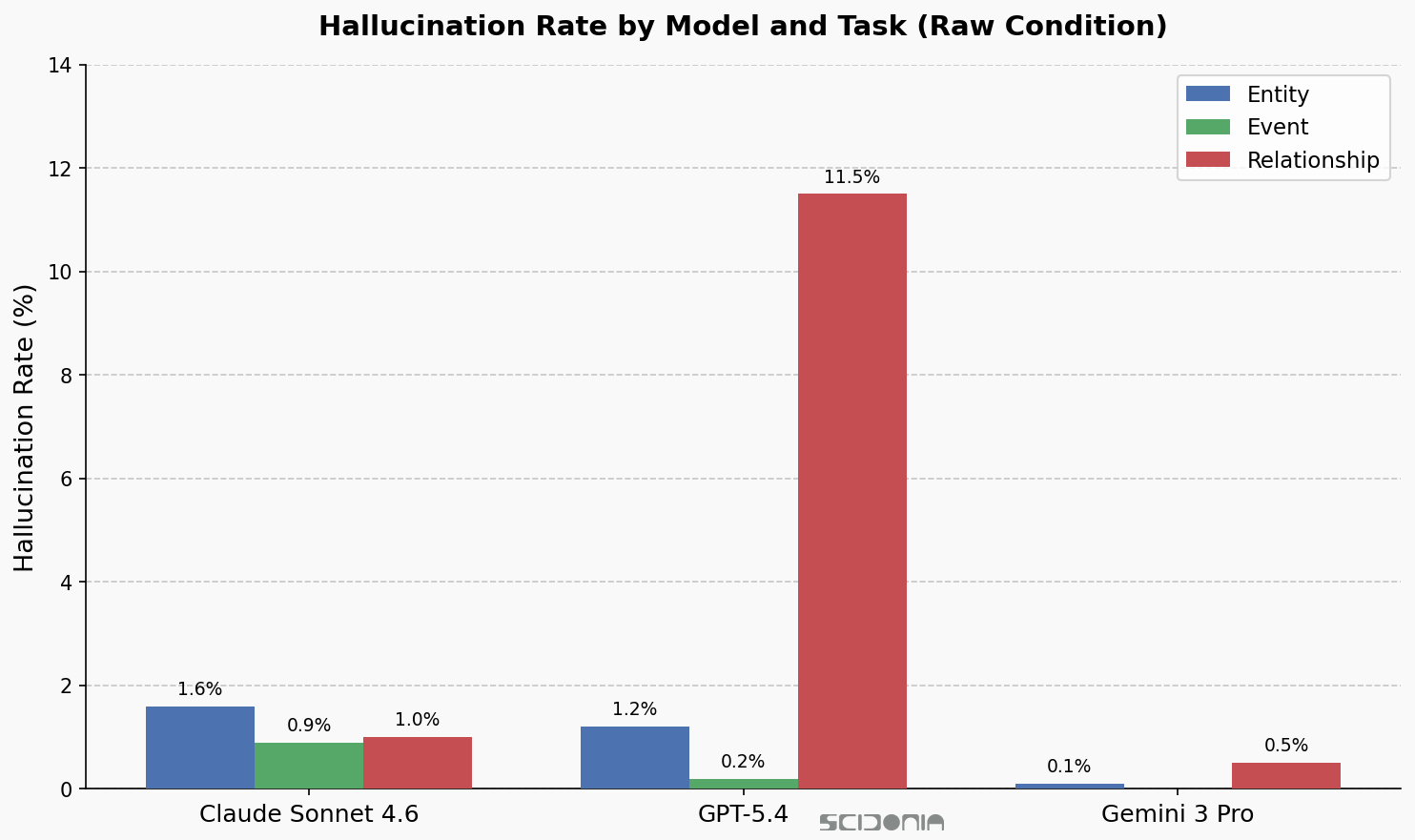
Entity extractions are usually well-grounded — below 2% across all models. Relationship extractions tell a very different story. GPT-5.4’s raw relationship unsupported extraction rate is 11.5%: roughly one in nine relationships it extracts has no support in the cited text. Claude sits at 1.0% for relationships, Gemini at 0.5%.
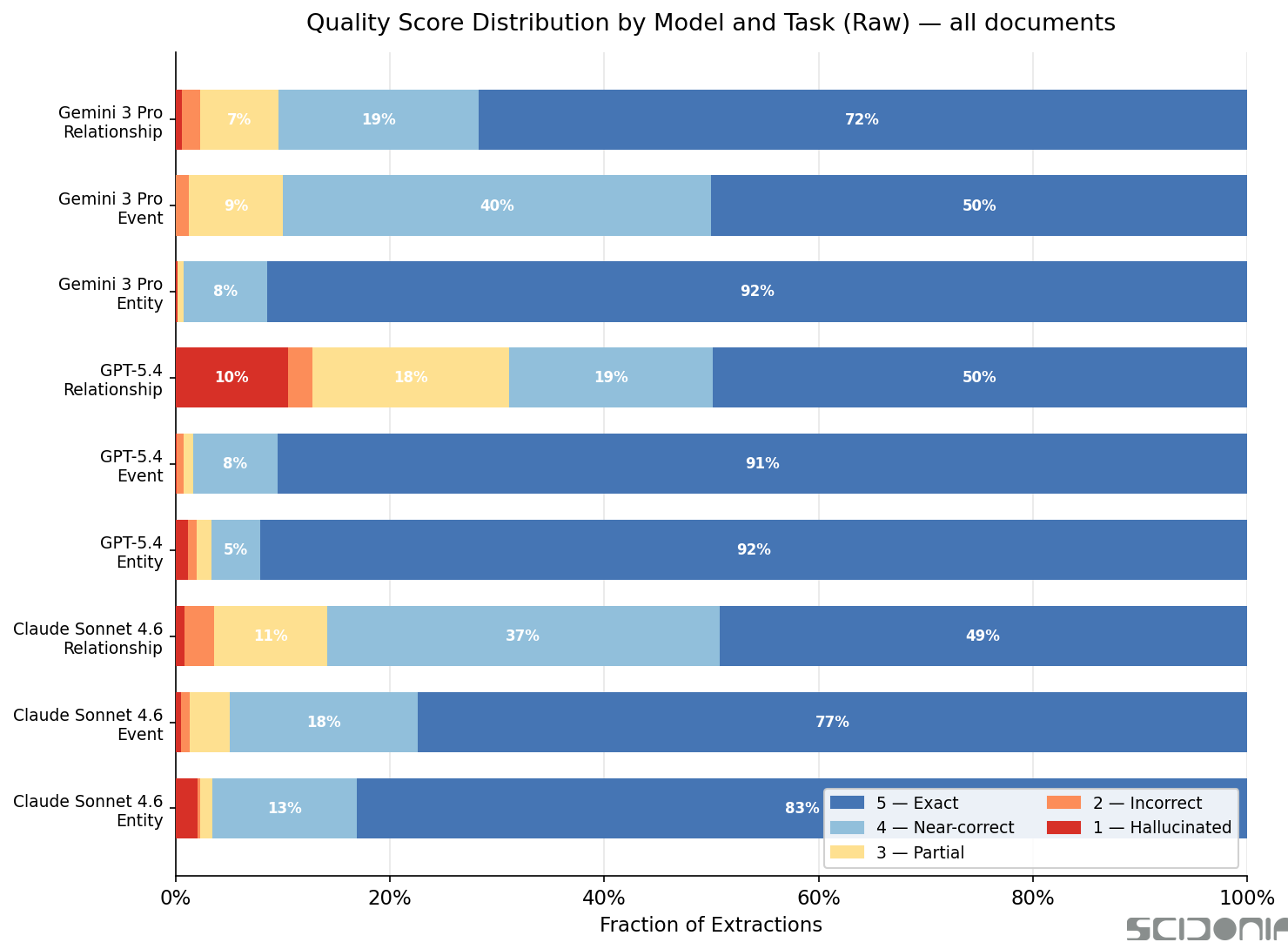
The Worst Case: 73% on a Single Document
Aggregate numbers can obscure how bad things get on individual documents. When we drilled into GPT-5.4’s relationship extractions on the Wikipedia article about large language models, the unsupported extraction rate was 73.2% — 169 out of 231 extracted relationships were not supported by the cited text.
The failure mode is specific and instructive — and the examples are not nonsense. The Wikipedia article is dense with citations. GPT attempted to model every citation as a relationship triple, extracting authorship links of the form Author --[AUTHORSHIP]--> Paper. It cited only the phrase containing the paper title. The author names were not in that phrase. But GPT knew the authors anyway — from its training data — and asserted them as document-derived facts.
Here is what those extractions look like, with their real-world truth status verified:
| Subject | Predicate | Object | Factually True? | Source |
|---|---|---|---|---|
Tom B. Brown | AUTHORSHIP | Language Models are Few-Shot Learners | ✅ Yes | arXiv:2005.14165 |
Rishi Bommasani | AUTHORSHIP | On the Opportunities and Risks of Foundation Models | ✅ Yes | arXiv:2108.07258 |
Jared Kaplan | AUTHORSHIP | Scaling Laws for Neural Language Models | ✅ Yes | arXiv:2001.08361 |
Anthropic | AUTHORSHIP | sleeper agents | ⚠️ Partly — lead author is Evan Hubinger et al. | arXiv:2401.05566 |
Swag | OTHER | HellaSwag | ✅ Yes — HellaSwag builds on SWAG | arXiv:1905.07830 |
Salesforce Agentforce | OTHER | sales data leakage | ❓ Plausible but unverified from cited phrase | — |
Every author-paper link GPT asserted is real. Tom B. Brown did lead the GPT-3 paper. Rishi Bommasani is the first author of the Foundation Models report. Jared Kaplan led the scaling laws paper. The Sleeper Agents paper is a genuine Anthropic research output, though attributing it simply to “Anthropic” rather than the lead author Evan Hubinger is an oversimplification. HellaSwag genuinely extends SWAG.
The model was not hallucinating. It was contaminating your knowledge graph with correct facts it learned elsewhere.
This is the core problem. When you build a knowledge graph from a specific corpus, you want facts that are grounded in that corpus — facts you can trace, verify, and cite. What GPT produced instead is a graph that mixes document-derived facts with parametric knowledge: things the model knows from training, silently injected and presented as if they came from your document. There is no flag, no warning, no distinction in the output.
Why Parametric Injection Is More Dangerous Than Pure Fabrication
If GPT had invented Tom B. Brown as a fictional author of a fictional paper, a fact-check would catch it quickly. Because the extracted facts are real, they pass surface-level review. The problem surfaces only when you try to trace the claim back to its source document — and discover the source phrase says nothing of the sort.
For knowledge graph navigation, this matters acutely. A user or agent asking “who wrote the scaling laws paper, according to our document corpus?” deserves an answer grounded in what the documents actually say — not in what GPT has memorised about the world. If the document cited the paper incorrectly, or under a different attribution, or in a context that matters for your specific use case, GPT will override it with its own version of the truth.
The consequences compound:
- Entity linking errors: A relationship asserted from parametric memory may link entities that your documents do not connect — or connect differently.
- Stale knowledge: The model’s training data has a cutoff. A paper whose authorship changed, a company that was acquired, a person whose role shifted — the model will inject the old fact.
- Domain-specific overrides: In legal, medical, or regulatory contexts, the document’s specific wording is what matters, not general world knowledge. Parametric injection silently substitutes the general for the specific.
- Broken provenance: Every surviving extraction should link back to the text that supports it. Parametric injections break that chain. You cannot audit what you cannot trace.
Claude’s Entity Problem: The Same Pattern
Claude Sonnet 4.6’s entity extractions on the same Wikipedia article had a 10.8% unsupported rate — 27 out of 249 entities. The same pattern applies: these are overwhelmingly real entities, cited from the wrong phrase.
- Kevin Esvelt — a real MIT professor (Associate Professor of Media Arts and Sciences, director of the Sculpting Evolution group, known for CRISPR gene drive research) — cited from a phrase about GPT-4o that does not mention him.
- South Park — genuinely referenced in the Wikipedia LLM article in the context of AI-generated content — cited from a phrase about something else entirely.
- Claude (Anthropic’s AI model) — obviously real, and present in the article — cited from a phrase about LLM controls that does not name it specifically.
- Hinglish, Hindi, English — real languages discussed in the article in the context of multilingual benchmarks — cited from a phrase listing other things.
None of these are invented. All of them are real. All of them are wrong as document-grounded extractions, because the phrase that was cited does not support them.
Cross-Checking Eliminates Almost All of It
The practical response is a second-pass verification step. For each extracted item, retrieve its cited phrases and ask the model whether the item is genuinely supported. In our evaluation, this cross-check pass drives unsupported extraction rates to near zero across all models and tasks:
| Condition | GPT-5.4 Relationship | Claude Entity |
|---|---|---|
| Raw | 11.5% | 1.6% |
| Cross-checked | 0.2% | 0.1% |
For GPT-5.4, cross-checking relationship extractions is not optional — it is the difference between an 11.5% contamination rate and a 0.2% one. The additional API cost is real but modest compared to the cost of building a knowledge graph on facts that are true about the world but not derived from your documents.
The cross-check also enforces provenance. Every surviving extraction is linked to the specific text that supports it. When a human or system later questions a graph entry, the evidence is retrievable. That traceability is not a nice-to-have — it is the mechanism by which you can distinguish a document-derived fact from a parametric injection.
What to Take Away
If you are using LLMs for entity extraction at scale, the key points are:
-
Most “hallucinations” are not invented — they are injected. The model knows real facts and asserts them against phrases that do not support them. Surface-level fact-checking will not catch this.
-
Parametric injection is dangerous precisely because the facts are often correct. A graph full of correct-but-ungrounded relationships will behave incorrectly as soon as your use case depends on document-specific context, provenance, or traceability.
-
Relationship extraction is the highest-risk task. All three models inject parametric knowledge into relationships more than entities. The structural complexity of triples makes it easy for a model to supply a subject or object it knows from training while citing a phrase that only contains part of the structure.
-
Citation-heavy documents are the failure mode to watch. Scientific papers, Wikipedia articles, and legal documents with embedded references trigger this pattern most severely. The model sees a paper title and completes the authorship from memory. On the Wikipedia LLM article, this produced a 73% unsupported extraction rate for relationships.
-
Cross-checking is a reliable fix. It eliminates nearly all unsupported extractions by forcing the model to confirm that the cited phrase actually contains the claimed information. For GPT on relationships, it is essentially mandatory.
-
Provenance is the defence. Knowing which phrase supports each extraction is what makes verification possible. Without it, you cannot distinguish a document-derived fact from a parametric injection — and your knowledge graph will silently accumulate both.
All code, results, and the full evaluation corpus are available at github.com/scidonia/ExtractionEval. This post is a follow-up to our PERSON entity extraction benchmark.