
Formal proof has always been expensive. Not just in the sense of requiring specialised expertise — though it does — but in the sense of requiring sustained, careful human attention. A single proof of a non-trivial theorem in Rocq might take a skilled researcher days or weeks.
We think that is changing. Here is what we measured.
The Benchmark: PCF Type Preservation
PCF — Programming Computable Functions — is a typed lambda calculus with fixpoints. It is a standard benchmark in programming language theory: small enough to be tractable, complex enough to be meaningful. We extended it with mutable references, which makes it substantially harder to prove and brings it closer to a real language like ML. Proving type preservation for PCF with references requires handling variable binding, substitution, store typing, and a non-trivial induction structure. It is not a completely toy problem.
We ran two frontier LLMs on this proof using rocq-piler, our open-source MCP-based Rocq proof assistant. Both sessions started from scratch with no human guidance beyond the initial problem statement.
The Results
| Model | Time | Cost | API Calls |
|---|---|---|---|
| DeepSeek v4 | ~21 minutes | $0.06 | 83 |
| Claude Opus 4.8 | ~14 minutes | $6.80 | 98 |
Both completed the proof. Claude was faster. DeepSeek cost 100× less — it required more API calls to find its way through the proof, but the per-token cost is low enough that the total came out at six cents versus $6.80.
Six cents. That is what a mechanised proof of a standard PL theory result costs today on a capable reasoning model. The question of whether to add formal verification to a project is no longer a question about budget.
Token Usage
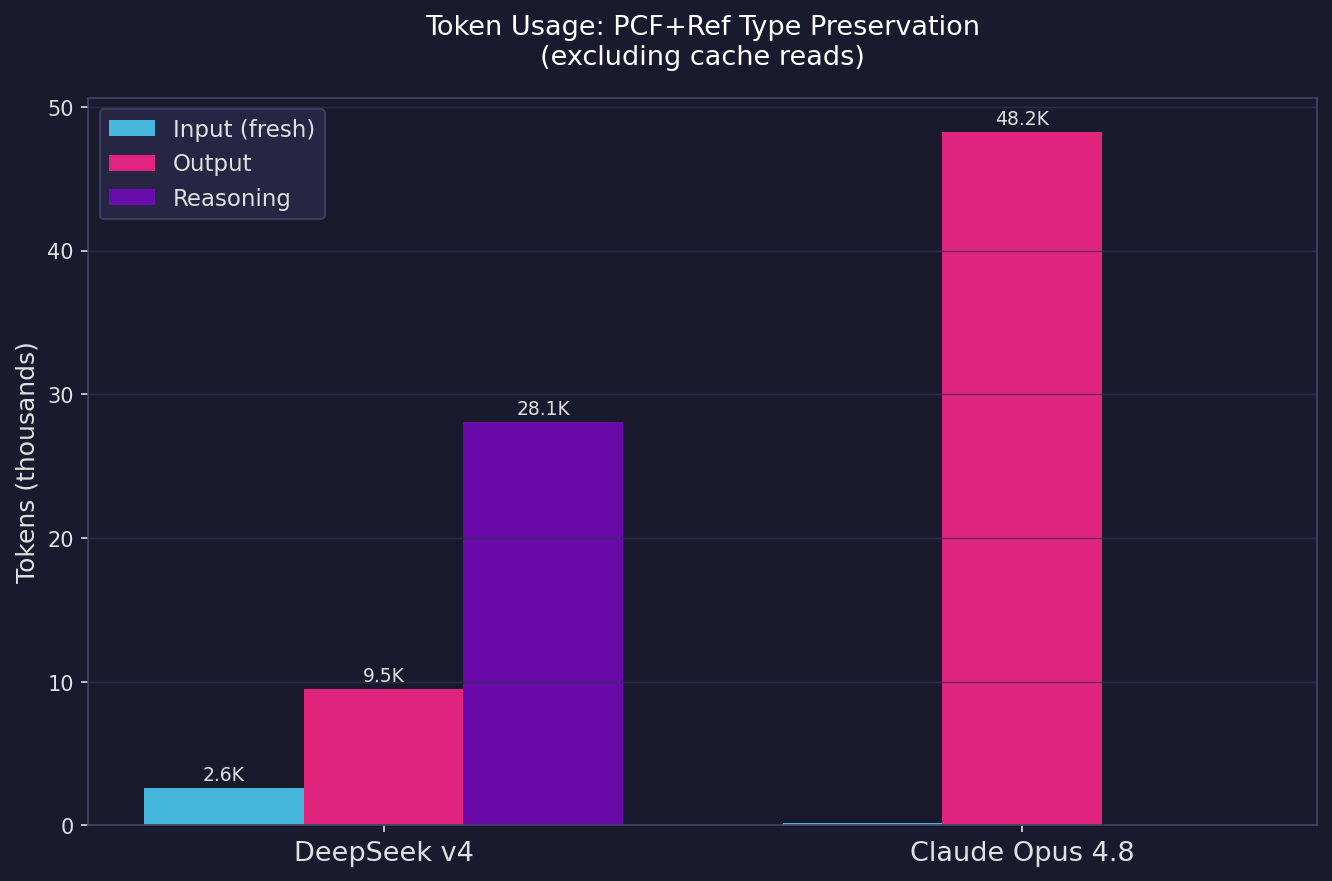
Cache reads dominate the billing in both runs but are excluded here to show the active token usage. DeepSeek spent most of its non-cache tokens on reasoning (28K) — thinking through proof steps before acting. Claude produced nearly 5× more output tokens (48K), reflecting a more verbose tactic-writing style. DeepSeek’s per-token costs are a fraction of Claude’s, which is where the 100× cost difference comes from despite comparable total token counts.
The Videos
Both runs were recorded at 10× speed.
DeepSeek v4 — PCF type preservation (~21 minutes real time)
Claude Opus 4.8 — PCF type preservation (~14 minutes real time)
How rocq-piler Works
The efficiency of these runs comes from the ergonomics of rocq-piler. The key design decisions:
Hash-addressed proof goals. Each open goal in a proof session is assigned a short hash. The LLM can target a specific admit by hash rather than navigating by position, which means multiple goals can be worked on in parallel and in any order. This cuts the token overhead of the heal loop — the cycle of inspecting goals, attempting tactics, and recovering from failures.
Consistent proof state via coq-lsp. The proof state is maintained by coq-lsp, which provides a live, authoritative view of what Rocq actually believes at any point. The LLM never works from a stale or inconsistent state. If a tactic fails, the state reverts cleanly. This eliminates a whole class of errors that appear in naive LLM-Rocq integrations where the model loses track of what has been proved.
Parallel goal closure. The close_admits tool accepts a portfolio of {hash: tactic} mappings and applies them in batch. Each attempt is a speculative dry-run first — if it closes the goal, the edit is committed; otherwise the admit is left untouched. The LLM can dispatch a whole class of routine goals in a single tool call rather than looping over them one by one.
stratify for case splits. The stratify tool runs a skeleton tactic (e.g. induction Hstep; intros; inversion Ht; subst), closes the easy cases automatically from a portfolio of standard tactics, and labels the survivors as named, hash-addressable admit blocks. The LLM gets a clear map of what remains rather than an undifferentiated list of subgoals.
What This Means
The cost of a mechanised proof is no longer a meaningful barrier. $0.06 for PCF type preservation means formal verification is cheaper than the CI run that checks your tests. The remaining barrier is knowing what to prove and how to state it. That is the problem of specification, not proof. And specification is what humans are best positioned to provide.
The Bigger Picture
Software now accounts for a substantial fraction of global economic activity — the global software industry alone is estimated at over $700 billion annually, and that is before counting the far larger value embedded in software-dependent systems across finance, healthcare, infrastructure, and manufacturing. Every one of those systems ships bugs. Some of those bugs are catastrophic. The reason we tolerate this is not that we want to. It is that rigorous formal verification has historically been too expensive to apply routinely.
That changes when proof costs cents. You can now pay a machine to certify the correctness of a property for less than it costs to file a bug report. It becomes cheaper to prove a postcondition holds than to investigate the incident that happens when it doesn’t.
The most important domain where this matters is software development itself. And the mechanism is vericoding — using verification to drive AI-generated code, insisting on proved properties rather than hoping for correct ones. LLMs write the implementation; the prover checks it; the human agrees on the specification. As LLMs write more of the code, the bottleneck shifts entirely to specification. Commoditised proof means that once you have the specification, checking it costs almost nothing.
This is still early. The proofs being run today are well-studied academic examples. But the economics are already there, and the tooling is improving fast. Vericoding is going to be a large part of how software gets built. We are at the point where the cost of proof is no longer the reason not to do it.
The remaining excuse is not knowing what to prove. That is a harder problem. But it is a much better problem to have.